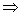 摑寁妛 傊栠傞
摑寁妛 傊栠傞乮侾乯 曣廤抍偺暯嬒偺揰悇掕
-
曣廤抍偺暯嬒抣偼丄 昗杮廤抍偺暯嬒抣偵嬤帡偟傑偡丅
-
丂 暯嬒抣
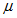 ( 偙偺抣偼岞昞偝傟偰偄側偄 ) 丄 昗弨曃嵎
( 偙偺抣偼岞昞偝傟偰偄側偄 ) 丄 昗弨曃嵎 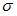 ( 偙偺抣偼岞昞偝傟偰偄傞 ) 偺曣廤抍偐傜丄 僒儞僾儖
( 偙偺抣偼岞昞偝傟偰偄傞 ) 偺曣廤抍偐傜丄 僒儞僾儖 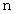 屄傪柍嶌堊偵拪弌偟傑偡丅 偦偟偰偦偺昗杮偺暯嬒抣傪
屄傪柍嶌堊偵拪弌偟傑偡丅 偦偟偰偦偺昗杮偺暯嬒抣傪 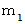 偲偟傑偡丅 偙偙偐傜愭偼幚嵺偵偟側偔偰偄偄偺偱偡偑丄偦偺僒儞僾儖傪尦偵栠偟偰偐傜丄傑偨摨偠偙偲傪偟偰偦偺暯嬒抣傪
偲偟傑偡丅 偙偙偐傜愭偼幚嵺偵偟側偔偰偄偄偺偱偡偑丄偦偺僒儞僾儖傪尦偵栠偟偰偐傜丄傑偨摨偠偙偲傪偟偰偦偺暯嬒抣傪 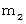 偲偟傑偡丅 偦偺僒儞僾儖傪尦偵栠偟偰偐傜丄 傑偨摨偠偙偲傪偟偰偦偺暯嬒抣傪
偲偟傑偡丅 偦偺僒儞僾儖傪尦偵栠偟偰偐傜丄 傑偨摨偠偙偲傪偟偰偦偺暯嬒抣傪 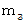 偲偟傑偡丅 偙偺傛偆偵偟偰偨偔偝傫偨偔偝傫旕忢偵偨偔偝傫廤傔偨昗杮暯嬒偺暯嬒傪偲傝傑偡偲丄偦傟偼 偵側傝傑偡丅墶幉偵偦傟偧傟偺昗杮暯嬒抣傪偲傝丄廲幉偵偦偺搙悢傪偲偭偰僌儔僼偵偟傑偡丅 偙傟傪 乽 昗杮暯嬒偵偮偄偰偺妋棪暘晍 乿 偲尵偄傑偡丅 偡傞偲偦傟偼丄 暯嬒抣 丄 昗弨曃嵎
偲偟傑偡丅 偙偺傛偆偵偟偰偨偔偝傫偨偔偝傫旕忢偵偨偔偝傫廤傔偨昗杮暯嬒偺暯嬒傪偲傝傑偡偲丄偦傟偼 偵側傝傑偡丅墶幉偵偦傟偧傟偺昗杮暯嬒抣傪偲傝丄廲幉偵偦偺搙悢傪偲偭偰僌儔僼偵偟傑偡丅 偙傟傪 乽 昗杮暯嬒偵偮偄偰偺妋棪暘晍 乿 偲尵偄傑偡丅 偡傞偲偦傟偼丄 暯嬒抣 丄 昗弨曃嵎  偺惓婯暘晍偵側偭偰偄傑偡丅
偺惓婯暘晍偵側偭偰偄傑偡丅丂 偟偨偑偭偰丄 嵟弶偺挷嵏偺 値 屄偺昗杮偺暯嬒乮m1乯傪 倣 偲偟偰丄
 偲抲偔偲丄
偲抲偔偲丄 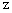 偼乽 昗弨惓婯暘晍 乿偵廬偄傑偡丅
偼乽 昗弨惓婯暘晍 乿偵廬偄傑偡丅丂 昗弨惓婯暘晍昞傛傝丄
丂丂丂丂丂
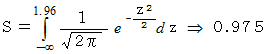
丂丂丂丂丂
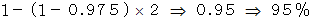
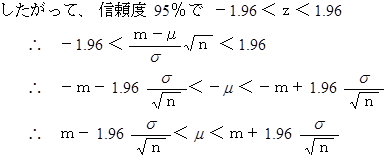
丂 埲忋偐傜丄 曣廤抍偺暯嬒抣偑柧傜偐偱側偔偰丄 曣廤抍偺昗弨曃嵎偑柧傜偐偵側偭偰偄傞偲偒丄 曣廤抍偺暯嬒抣 兪 偼95%偺妋棪偱
 偵擖傞偙偲偑傢偐傝傑偡丅 倣 偼昗杮暯嬒偱偡丅 偙傟傪嬫娫悇掕偲偄偄傑偡丅 嬫娫悇掕偼 乽 昗杮偺暯嬒偑 倣 偩偐傜 曣廤抍偺暯嬒抣傕 倣 偱偁傠偆丅乿 偲悇應偡傞揰悇掕偺傛偆偵扨弮側傕偺偱偼偁傝傑偣傫丅
偵擖傞偙偲偑傢偐傝傑偡丅 倣 偼昗杮暯嬒偱偡丅 偙傟傪嬫娫悇掕偲偄偄傑偡丅 嬫娫悇掕偼 乽 昗杮偺暯嬒偑 倣 偩偐傜 曣廤抍偺暯嬒抣傕 倣 偱偁傠偆丅乿 偲悇應偡傞揰悇掕偺傛偆偵扨弮側傕偺偱偼偁傝傑偣傫丅 丂 埲忋偺悇掕偼丄 曣廤抍偺暯嬒抣偑晄柧偱偡偑昗弨曃嵎偑柧傜偐偵側偭偰偄傞応崌偵梡偄傜傟傑偡丅 偟偐偟丄 幚嵺偼曣廤抍偺暯嬒抣傕昗弨曃嵎傕柧傜偐偵側偭偰偄側偄偲巚偄傑偡丅 偦偙偱丄 曣廤抍偺暯嬒抣傪悇掕偡傞偨傔偵 倲 暘晍 偑梡偄傜傟傑偡丅
丂 惓婯暘晍偵廬偆曣廤抍偺暯嬒抣傪 兪 偲偟傑偡丅 偦偙偐傜柍嶌堊偵 値 屄偺昗杮傪嵦庢偟傑偡丅 昗杮偺暯嬒偑 倣 偱丄 昗弨曃嵎偑 倵 偱偁偭偨偲偟傑偡丅 偙偺忣曬偐傜 兪 傪悇掕偟傑偡丅
丂丂丂丂
丂
丂丂丂丂丂丂
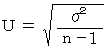
丂 忋婰偺 倲 偼 帺桼搙 値亅侾 偺 倲 暘晍 偵廬偄傑偡丅
丂 椺偊偽丄 値 亖 101丂偺偲偒丄 帺桼搙100 偺 倲 暘晍偼 怣棅搙95%偱丄
亅 1.9840丂亝丂倲丂亝丂1.9840丂側偺偱丄 師偺傛偆偵側傝傑偡丅
丂丂丂丂
偙偆偟偰丄 曣廤抍偺暯嬒偼丄 怣棅搙俋俆亾偱丄
丂丂丂丂
偵偁傞偙偲偑悇掕偱偒傑偡丅
-
丂 曣廤抍偺暘嶶偼丄 昗杮廤抍偺晄曃暘嶶偵嬤帡偟傑偡丅
丂 晄曃暘嶶偲偼丄 昗杮偺暘嶶偵
-
丂 惓婯暘晍偵廬偆曣廤抍偺丄暯嬒抣傪 兪乮枹抦偱傕婛抦偱傕壜乯偲偟丄暘嶶傪 冃2乮枹抦乯偲偟傑偡丅 偦偙偐傜柍嶌堊偵 値 屄偺昗杮傪嵦庢偟傑偡丅 昗杮偺暯嬒偑 倣 偱丄 晄曃暘嶶偑 倀2 偱偁偭偨偲偟傑偡丅 偙偺忣曬偐傜 冃2 傪悇掕偟傑偡丅
丂丂丂丂
丂 忋婰偺 俿 偼 帺桼搙 値亅侾 偺 僇僀俀忔 (x2) 暘晍 偵廬偄傑偡丅
丂 椺偊偽丄 値 亖 10丂偺偲偒丄 帺桼搙 9 偺 僇僀俀忔暘晍 偼 怣棅搙95亾偱丄
2.70丂亝丂x2丂亝丂19.0丂側偺偱丄 師偺傛偆偵側傝傑偡丅
丂丂丂丂
丂丂丂丂
-
丂 晄椙昳娷桳棪偑
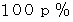 偺惢昳傪柍嶌堊偵 屄拪弌偟偰晄椙昳偑壗屄乮
偺惢昳傪柍嶌堊偵 屄拪弌偟偰晄椙昳偑壗屄乮 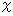 屄 乯擖偭偰偄傞偺偐傪挷嵏偟傑偟偨丅 摨偠偙偲傪壗搙傕壗搙傕孞傝曉偟偰1000夞偵搉傝挷嵏傪偟偨屻丄 墶幉偵 傪偲傝 廲幉偵 搙悢傪1000偱妱偭偨抣 傪偲偭偰僌儔僼傪嶌傝傑偟偨丅 偡傞偲偙偺僌儔僼偼丄 師偺妋棪暘晍傪帩偮擇崁暘晍偵嬤偄傕偺偵側傝傑偡丅
屄 乯擖偭偰偄傞偺偐傪挷嵏偟傑偟偨丅 摨偠偙偲傪壗搙傕壗搙傕孞傝曉偟偰1000夞偵搉傝挷嵏傪偟偨屻丄 墶幉偵 傪偲傝 廲幉偵 搙悢傪1000偱妱偭偨抣 傪偲偭偰僌儔僼傪嶌傝傑偟偨丅 偡傞偲偙偺僌儔僼偼丄 師偺妋棪暘晍傪帩偮擇崁暘晍偵嬤偄傕偺偵側傝傑偡丅丂丂丂丂丂
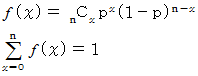
傑偨丄 偙偺僌儔僼偼師偺暯嬒偲昗弨曃嵎傪帩偮惓婯暘晍偵嬤偄傕偺偵傕側偭偰偄傑偡丅
丂丂丂丂丂

偦偙偱丄
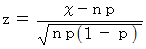 偲抲偔偲丄 偼 乽 昗弨惓婯暘晍 乿 偵廬偄傑偡丅
偲抲偔偲丄 偼 乽 昗弨惓婯暘晍 乿 偵廬偄傑偡丅丂 昗弨惓婯暘晍昞傛傝丄
丂丂丂丂丂
丂丂丂丂丂
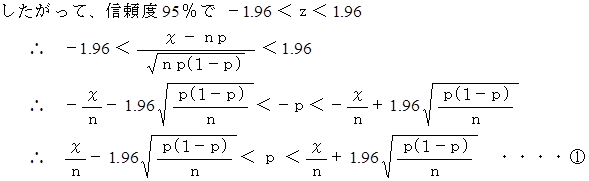
丂
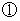 偵偮偄偰丄
偵偮偄偰丄 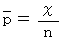 偲抲偒丄 儖乕僩撪偺
偲抲偒丄 儖乕僩撪偺 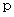 偵娭偟偰
偵娭偟偰 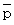 偱嬤帡偡傞偲丄 師偺傛偆偵側傝傑偡丅
偱嬤帡偡傞偲丄 師偺傛偆偵側傝傑偡丅丂丂丂丂丂
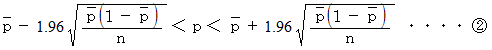
丂 偝偰丄 偙偺挷嵏偱偼丄 慡懱偱丄
 偺昗杮傪廤傔偰偄傑偡丅 偙偺偲偒偵弌偰偒偨晄椙昳偺憤寁傪
偺昗杮傪廤傔偰偄傑偡丅 偙偺偲偒偵弌偰偒偨晄椙昳偺憤寁傪  偲偟傑偡偲丄
偲偟傑偡偲丄 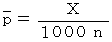 偱嬶懱揑側 偺抣偑寛傑傝傑偡偺偱丄 幃
偱嬶懱揑側 偺抣偑寛傑傝傑偡偺偱丄 幃 傛傝
傛傝 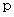 偺斖埻偑媮傑傝傑偡丅 偼乽 昗杮斾棪 乿丄 偼乽 曣斾棪 乿偲尵傢傟傑偡偺偱丄 崱夞偼乽 昗杮斾棪 乿偐傜乽 曣斾棪 乿傪悇掕偟偨偙偲偵側傝傑偡丅
偺斖埻偑媮傑傝傑偡丅 偼乽 昗杮斾棪 乿丄 偼乽 曣斾棪 乿偲尵傢傟傑偡偺偱丄 崱夞偼乽 昗杮斾棪 乿偐傜乽 曣斾棪 乿傪悇掕偟偨偙偲偵側傝傑偡丅丂偱偼丄 椺戣傪夝偄偰傒傑偟傚偆丅
丂 撪妕巟帩棪傪1000恖偺惉恖傪柍嶌堊偵拪弌偟偰挷嵏偟偨偲偙傠丄 偪傚偆偳50%偺恖偑巟帩偟偰偄傑偟偨丅 偙偺寢壥偐傜丄 撪妕巟帩棪傪怣棅搙95%偱悇掕偟偰傒傑偟傚偆丅 摨偠偙偲傪100夞孞傝曉偟偰丄 墶幉偵巟帩幰悢偲偟偰侽恖偐傜1000恖偺帺慠悢傪偲傝丄 廲幉偵搙悢傪100偱妱偭偨悢傪偲偭偰丄 僌儔僼傪嶌偭偨偲偟傑偟傚偆丅 偡傞偲偙偺僌儔僼偼丄 師偺暯嬒偲昗弨曃嵎傪帩偮惓婯暘晍偵嬤偄傕偺偵側傝傑偡丅
丂丂丂丂
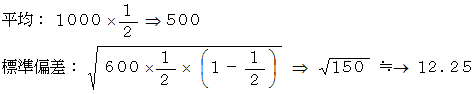
幃
傛傝丄 丂丂丂丂丂
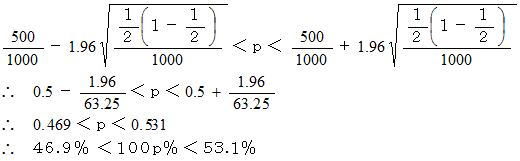
丂 偟偨偑偭偰丄 撪妕巟帩棪偼怣棅搙95亾偱
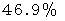 偐傜
偐傜 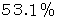 偺娫偵偁傞偲悇掕偱偒傑偡丅
偺娫偵偁傞偲悇掕偱偒傑偡丅丂 偱偼丄 撪妕巟帩棪傪怣棅搙95%偱
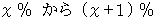 偺嫹偄娫偵偁傞偲悇掕偱偒傞傛偆偵偡傞偨傔偵偼丄 偝傜偵壗恖偺挷嵏傪捛壛偟側偗傟偽側傜側偄偱偟傚偆偐丠
偺嫹偄娫偵偁傞偲悇掕偱偒傞傛偆偵偡傞偨傔偵偼丄 偝傜偵壗恖偺挷嵏傪捛壛偟側偗傟偽側傜側偄偱偟傚偆偐丠丂丂丂丂丂
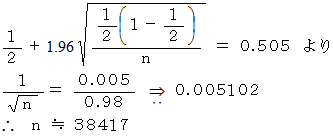
偟偨偑偭偰丄 偝傜偵37417恖偺挷嵏傪峴傢側偗傟偽側傝傑偣傫丅
-
丂 俀偮偺曣廤抍偺暯嬒抣偵桳堄嵎偑偁傞偐偳偆偐傪専掕偡傞偲偒丄 曣廤抍偺昗弨曃嵎偑晄柧側偲偒偼丄 倲 暘晍傪棙梡偟傑偡偑丄 曣廤抍偺昗弨曃嵎偑柧傜偐側偲偒偼惓婯暘晍傪棙梡偟傑偡丅 偙偙偱偼丄 惓婯暘晍傪梡偄偨曣廤抍偺暯嬒嵎偺悇掕偺曽朄傪徯夘偟傑偡丅
丂丂丂曣廤抍俙 丗丂暯嬒抣丂兪侾丂 暘嶶 冃侾俀
丂丂丂曣廤抍俛 丗丂暯嬒抣丂兪俀丂 暘嶶 冃俀俀
丂丂丂曣廤抍俙 偺昗杮 丗丂昗杮悢 値侾丂丂暯嬒抣 倣侾
丂丂丂曣廤抍俛 偺昗杮 丗丂昗杮悢 値俀丂丂暯嬒抣 倣俀
丂 妋棪曄悢丂倣侾 亅 倣俀丂偼丄丂暯嬒 兪侾 亅 兪俀丂 昗弨曃嵎
丂丂丂丂丂
偟偨偑偭偰丄 怣棅搙 95% 偱丄 師偺幃偑惉傝棫偪傑偡丅
丂丂丂
|
丂曣廤抍俙偺昗杮 |
丂曣廤抍俛偺昗杮 |
|
丂丂丂丂128丂 |
丂丂丂丂113 |
| 丂丂丂丂136 | 丂丂丂丂126 |
| 丂丂丂丂138 | 丂丂丂丂132 |
| 丂丂丂丂140 | 丂丂丂丂135 |
| 丂丂丂丂147 | 丂丂丂丂139 |
| 丂丂丂丂154 | 丂丂丂丂156 |
|
丂暯嬒抣丂140.5 |
丂暯嬒抣丂133.5 |
丂丂丂丂曣廤抍俙 偺暘嶶 丗 丂64.0
丂丂丂丂曣廤抍俛 偺暘嶶 丗 144.0
丂 幃
丂丂丂丂丂
丂 埲忋傛傝丄 怣棅搙 95% 偱丄 暯嬒抣偺嵎偼 1.11 乣 12.89 偺斖埻偵偁傞偙偲偑悇掕偝傟傑偟偨丅 偙偺斖埻偺拞偵侽偼擖偭偰偄傑偣傫丅 偟偨偑偭偰丄 怣棅搙 95%偱丄 俀偮偺曣廤抍偺暯嬒抣偼堎側傞偲尵偊傑偡丅